The Pseudo-Bot Reviewer
In mid-April, he was #2 on the reviewer leaderboard. Six weeks later, he was #1 - with two bots right behind him, operating at roughly the same scale.
Acknowledgment: I want to thank Stephen Gillie for taking the time to speak with me, share insight into how his review workflow actually works, and allow me to write about it publicly. What looked like an anomaly in the data became much more interesting after that conversation.
Preface
After building the MVP of GitQuick, I wanted to test whether it could do the thing I originally built it for: find patterns in pull request review data. Not just produce charts. Not just count activity. But surface system-level signals: review load, merge friction, bottlenecks, and places where work quietly piles up.
And what better test than large open-source organizations on GitHub? The biggest useful target I found was Microsoft.
In the May snapshot, Microsoft's GitHub organization had roughly 6,000 repositories and around 37,000 pull requests in the analysis. The April numbers were in the same range.
Nothing fancy. I was just trying to understand how review work was distributed.
- Who reviews what?
- How fast does review happen?
- ..etc
The usual things you ask yourself as a curious software engineer looking at a system from far enough away that it starts to look less like people and more like a shape.
And in mid-April, I thought I had found the shape.
One name stood out: stephengillie. He was ranked #2 on the reviewer leaderboard, behind Copilot. More surprisingly, he alone had made roughly as many reviews as reviewers #3 to #10 combined. My first assumption was: this must be a bot. But the name did not look like one. So I clicked the profile. To my surprise, it was not a bot.
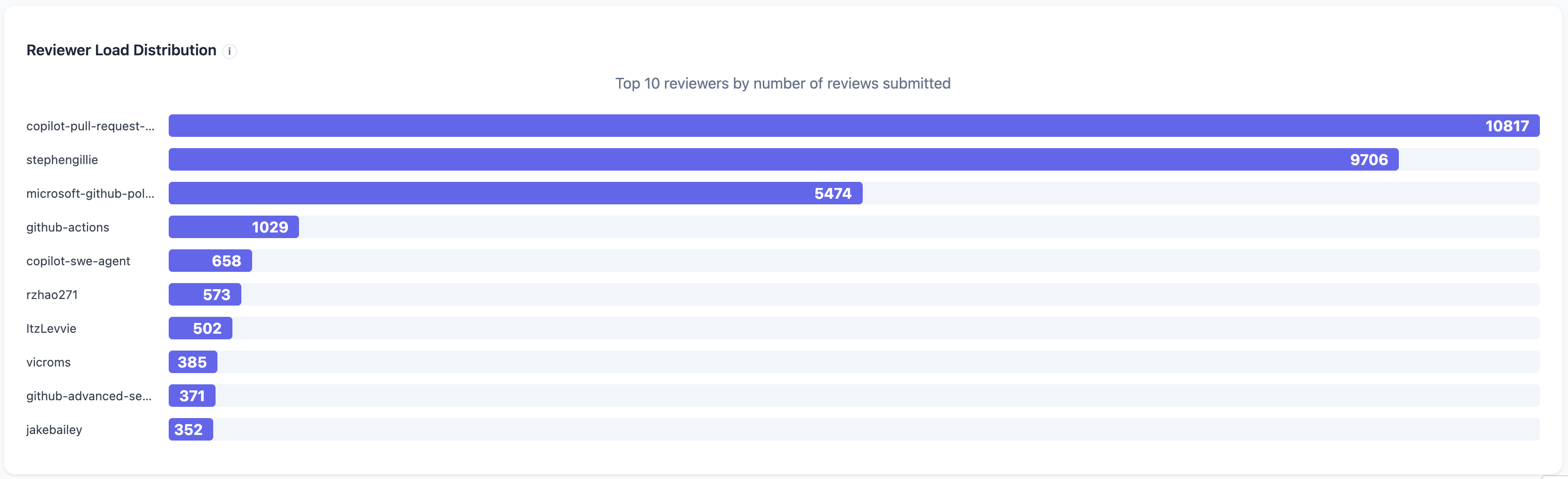
Then I got busy, went on vacation, and did not publish the post. By the end of May, the latest analysis showed even more extreme numbers. The story I originally planned to tell was already outdated.
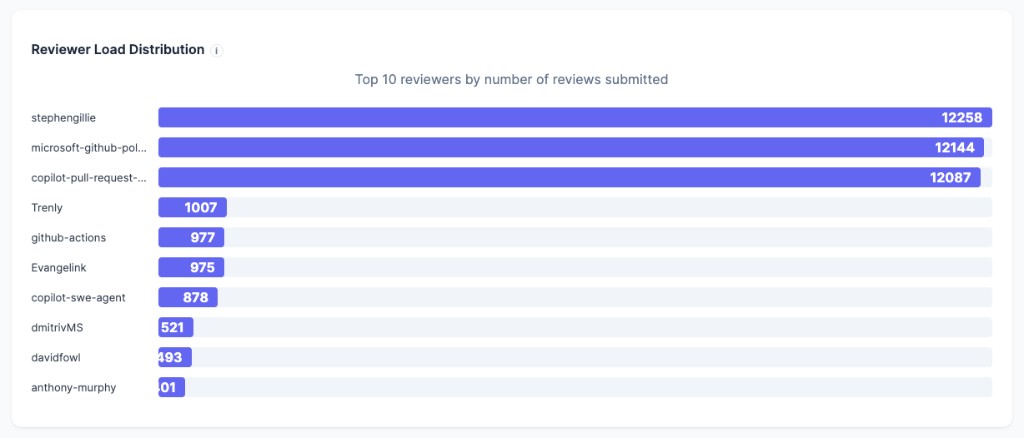
But it became a more interesting story.
First Contact With the Pseudo-Bot
When I first saw the numbers in April, I thought something might be broken in my pipeline. A single non-bot reviewer showing up at that scale looked suspicious. Either the data was wrong, the classification was wrong, or something very unusual was happening.
So I reached out. Mostly out of curiosity. Fortunately, the answer was not: "I just work very hard." The person behind the account, Stephen, was not manually grinding through thousands of pull requests.
He was operating a system. From what he described, the workflow included:
- A scheduler scanning pull requests every 30 minutes
- Automated validation pipelines extracting failure signals
- VM orchestration for installations, virus scans, resets, and checks
- Auto-approval logic for safe cases
- A human sitting on top of the process, handling edge cases and confirming outcomes
At that point, calling this simply "a reviewer" feels inaccurate. It is more like a human-controlled review system. Or, less formally: a pseudo-bot.
Why This Matters
From the outside, the data appears to say:
One person is reviewing a large share of the pull requests in one organization.
That usually sounds bad.
It looks like:
- a bottleneck
- a dependency risk
- or a hero pattern
And in some organizations, that interpretation might probably be correct.
If one person is manually reviewing a third of an organization's pull request activity, I would not call that a healthy system.
But in this case, the better interpretation is different:
A large part of the review process has been systematized.
The human is not doing the bulk of the repetitive work. The system is. Stephen is not just "reviewing a lot." He has identified a review process that can be automated, built the surrounding machinery, and scaled it.
That is a very different signal.
Most tools - including the first version of GitQuick - treat reviewers as either human or bot. But this case is neither. It is a third category:
A human amplified by a system.
And that is where naive metrics start to lie.
The Problem With Counting Reviewers
Review count is easy to measure. Effort is not.
A high review count can mean many different things:
- someone is overloaded
- someone is doing shallow reviews
- or someone has built automation around the review process
The trap is that the number alone does not tell you which one is true.
A dashboard can show that one reviewer is responsible for a huge percentage of activity. But without context, the same number can point to completely different realities. And that matters because the action you take depends entirely on the interpretation.
If this were a real human bottleneck, the response might be:
- distribute review ownership
- add more maintainers
- ...
- etc.
But if this is automation-amplified review, the more interesting questions become:
- What part of the review process was automatable?
- Can this model be reused elsewhere?
- Which checks still require human judgment?
That is a completely different conversation.
The Mind Shift
Stephen did not break my model. He's rather extended it. GitQuick was built to look for patterns in pull request data. And this was exactly that: a pattern.
But the interpretation needed to become more precise. Before this, I was mostly thinking in terms of:
human reviews vs bot reviews
Now I think the more useful distinction is closer to:
manual review work vs automated review work
Because a "human" reviewer can operate at bot scale without actually behaving like a bot. And a bot can still represent a human-designed review policy, workflow, or quality gate.
The better question is not only:
Who reviewed this?
It is also:
What kind of system produced this review?
That is the part I now want GitQuick to understand better.
The Bigger Lesson
This is not a story about one person reviewing thousands of pull requests. It is not really about throughput either. It is about ingenuity. It is about seeing a repetitive, high-volume process and refusing to handle it manually forever.
It is also not a claim that every pull request review process can be automated in the same way. Most software reviews still need human judgment. Context matters. Architecture matters. Product intent matters. Risk matters.
But some parts of review are repetitive. Some parts are mechanical. Some parts are validation, not judgment. And when those parts become frequent enough, they should probably stop being human work. That is what made Stephen's case interesting to me.
At first glance, the data looked like a warning sign. After talking to him, it looked more like a design pattern.